Batch-size scaling experiment for Adam (square-root rule): configs + analysis#539
Batch-size scaling experiment for Adam (square-root rule): configs + analysis#539jlamypoirier wants to merge 3 commits into
Conversation
Self-contained example under examples/batch_size_scaling/ testing whether small-batch Adam training reproduces large-batch under the square-root (SDE) scaling rule, vs the keep-lr/scale-beta2 paper rule. Includes prepare/warmup/ arm configs, a README arm matrix, and ANALYSIS.md (theory + predictions + preliminary results). Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
ANALYSIS: on a single epoch the training loss is effectively a held-out measure (each batch scored before it is trained on), so the broken eval-loss logging (#538) is not a real limitation; only the excluded re-read prefix is memorization-contaminated. Adds two loss-vs-tokens plots (all arms with the re-read boundary, and the square-root-rule equivalence overlay). Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
|
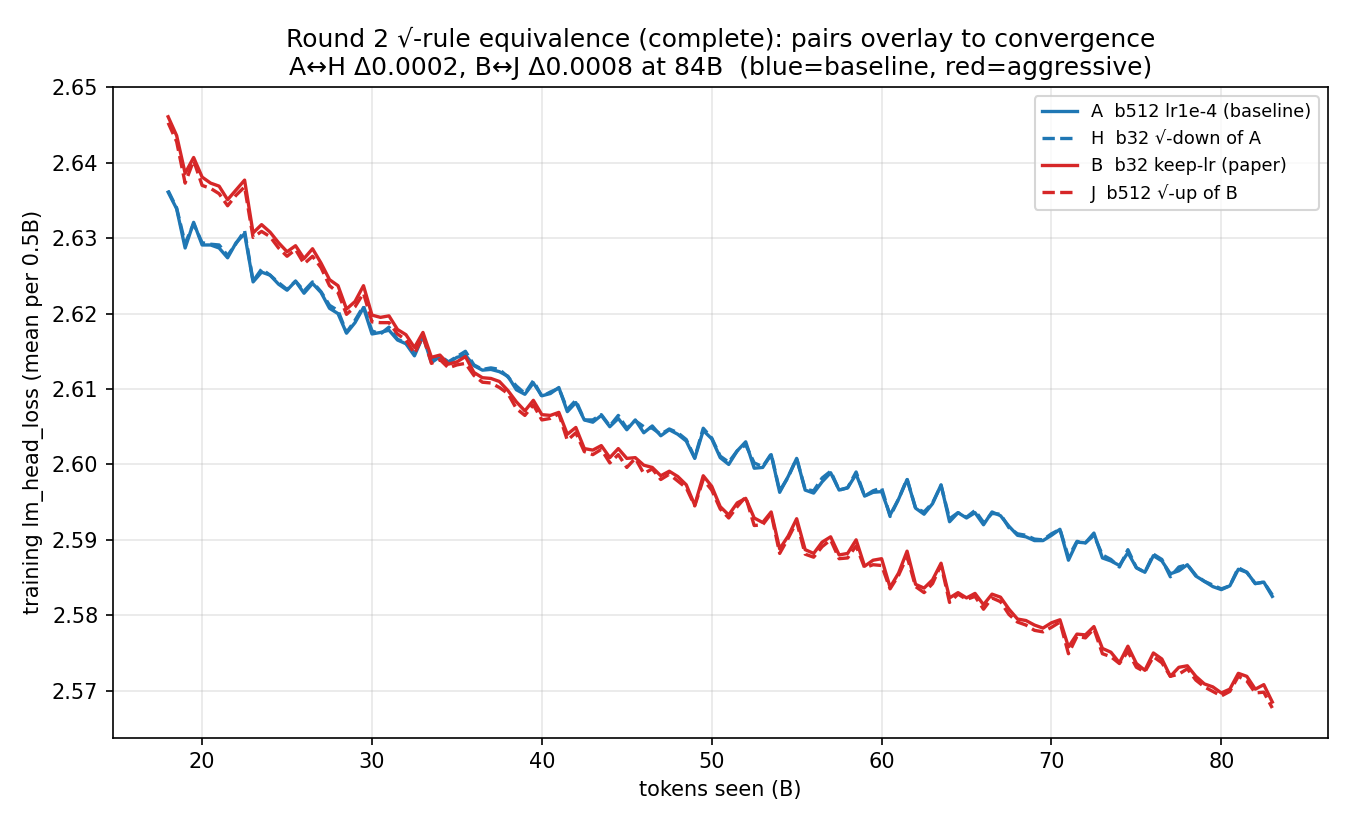
Claude Opus 4.8 — Round 2 results (COMPLETE). All 8 arms ran to 83.9B tokens; the conclusions below are final (binned), and held to convergence. Setup recapEight arms branched (weights only, cold optimizer) from a checkpoint ~18B tokens in, batch ratio 16 (b=32 ↔ b=512), constant lr, shared shuffled stream. Two √-rule pairs anchor the comparison: scale down from the b=512 baseline (A → H) and up from the b=32 keep-lr arm (B → J). The √-rule reproduces large-batch training — to convergenceIn the noise-dominated regime (where the SDE rule is derived), the √-scaled small-batch arms overlay their large-batch partners the whole way:
At the final 84B point (binned): A ↔ H Δ 0.0002 and B ↔ J Δ 0.0008 — about 15× below the ~0.014 gap between the two operating points. The √-rule maps each batch size onto the other's trajectory, at both a conservative and an aggressive operating point, start to finish. All arms, with the re-read boundary
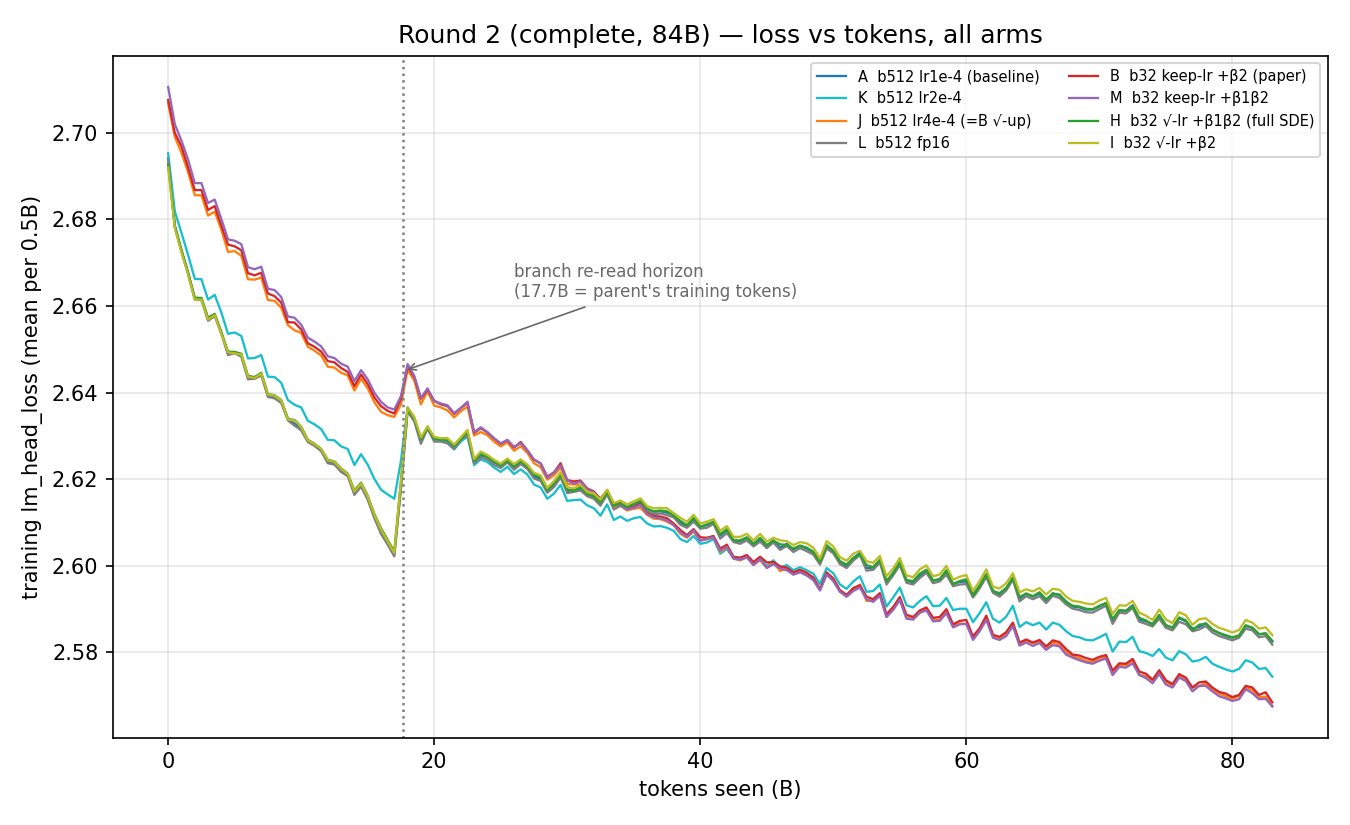
The sharp step at 17.7B is not a data-quality artifact — it is the branch parent's training horizon (the shuffle is seeded independently of batch size, so the children replay the parent's already-seen data until 17.7B, then jump to the true level on novel data). All comparisons are windowed past it. (Lesson — use a fresh data seed when branching — is in Secondary signals (small, consistent through convergence)
Training vs validationThese are first-epoch runs, so training loss is effectively a held-out measure — each batch is scored before the model trains on it, on never-before-seen data. So the broken validation-loss logging (#538) does not limit these conclusions; the only memorization-contaminated region is the excluded re-read prefix. Full theory, predictions, and caveats are in 🤖 Generated with Claude Code |
Round 2 ran to completion (all 8 arms at 83.9B tokens); the square-root-rule equivalence held to convergence (A↔H Δ0.0002, B↔J Δ0.0008, binned, at 84B). Updates the two round-2 plots to the full run and adds a round-1 (signal- dominated, ratio 32) plot for contrast. Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
|
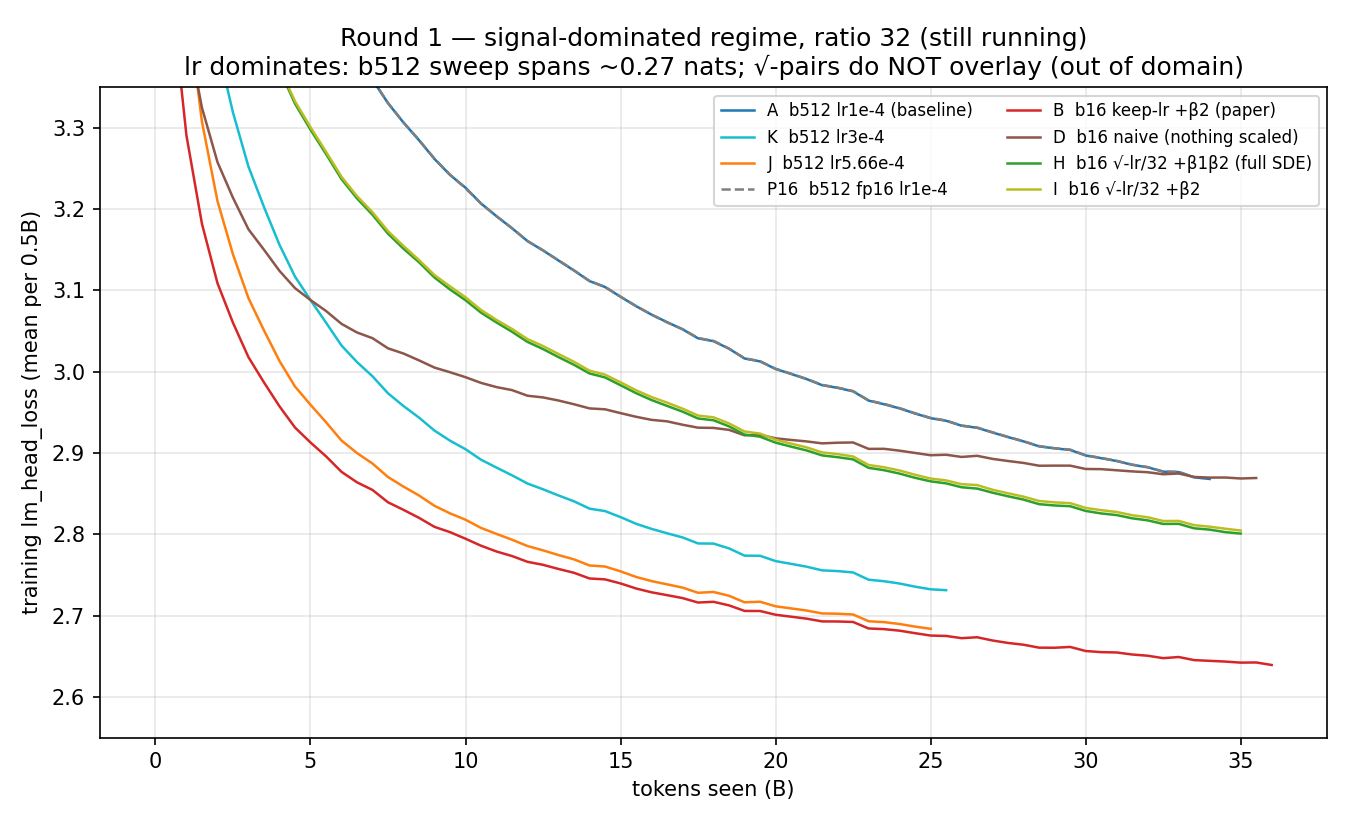
Claude Opus 4.8 — Round 1 results (the out-of-domain control; still running, ~25–36B tokens, arms at different points so compared at matched tokens). Round 1 branched the arms early (signal-dominated regime, loss starting ~3+), batch ratio 32. It's the contrast to the round-2 results above, and it behaves exactly as the regime framing predicts: the √-rule does not apply here, and learning rate dominates.
Learning rate dominates — the b512 sweep spans ~0.27 nats. At matched 24B tokens: A (lr 1e-4) = 2.95, K (3e-4) = 2.74, J (5.66e-4) = 2.69. The 1e-4 reference is badly under-tuned — which is why round 2 kept 1e-4 as the baseline but re-anchored the comparison deep in training rather than chasing the early optimum. The √-rule does not overlay here (as expected, out of domain). The √-down pair A↔H is ~0.08 apart at matched tokens — vs 0.0002 in round 2. In the signal-dominated regime the rule's noise-averaging mechanism isn't what governs, so the equivalence it guarantees doesn't kick in; the √-down small-batch arms (H/I, at lr 1e-4/√32 ≈ 1.8e-5) actually undertrain. Batch size: small-batch keep-lr (B, b16, lr 1e-4 + β2 scaled) = 2.68 beats the large-batch reference A = 2.95 — but that's A's under-tuning, not a batch-size law. Knobs: precision washes out exactly (A ≈ P16 to 0.0003); β1 is inert (H ≈ I). Both consistent with round 2's "secondary, small" reading, but here swamped by the lr effect. Takeaway: round 1 is the out-of-domain control — the √-rule's knobs have no leverage and the equivalence doesn't hold in the signal-dominated regime. That contrast is exactly what makes round 2 (noise-dominated, rule holds to convergence) the valid test, and RL / late training live in the round-2 regime. Theory and full discussion in 🤖 Generated with Claude Code |
Claude Opus 4.8 note (drafted via Claude Code): opening as a draft — the training runs are still going, so the Results section is marked preliminary.
Adds a self-contained example under
examples/batch_size_scaling/testing whether small-batch Adam training reproduces large-batch training when the hyperparameters are scaled by the square-root (SDE) rule (Malladi et al., 2205.10287), and how that compares to the "keep lr, scale β2" paper rule (Marek et al., 2507.07101).Separate concern from #525 (the layer-wise numerical-error tool) — this is full training runs on Qwen2.5-0.5B / FineWeb-Edu, not a per-step precision probe.
Contents
prepare.yaml/warmup.yaml/arm_base.yaml— tokenization, throwaway from-scratch warmup, and the shared arm base (per-arm overrides in the README).README.md— reproduction steps + arm matrix (the two √-rule pairs A↔H and B↔J).ANALYSIS.md— the theory (why the SGD linear rule fails for Adam, the √/SDE rule and its equivalence guarantee, equivalence-vs-optimality), predictions, and a preliminary Results section.Headline result (preliminary)
In the noise-dominated regime (deep in training — the regime the √-rule is derived for), the √-scaled small-batch arms overlay the large-batch trajectory: the pairs A↔H and B↔J match to ~0.0002–0.0006 nats, ~10× below the spread between operating points. Early on (signal-dominated) the rule's knobs wash out and it isn't even testable — which reframes batch-size effects there as an update-count/drift phenomenon, not the noise-averaging the rule addresses. Small secondary signals: β1-scaling helps slightly (favoring the full SDE rule over β2-only), and fp16 edges bf16. Full writeup and caveats in
ANALYSIS.md.Caveats
Runs ongoing / not converged; comparisons use training loss because validation-loss logging is currently broken (#538); single model + dataset. (W&B loss curves can be attached.)
🤖 Generated with Claude Code